
Naive Bayes Language Classifier (2020)
A naive Bayesian classifier implementation that classifies fragments of text according to language category.
Github repository link to my code
About the code
The script builds a set of 15 unigram language models from a set of files containing token counts for 1,500 of the types in each language. The log probability of each sentence (given a language) is generated and output to the console (see image below). The most probable language is also output to the console and labeled as the “result”. To calculate the (smoothed) log probability of each word in the 15 language samples, the following formula was used:
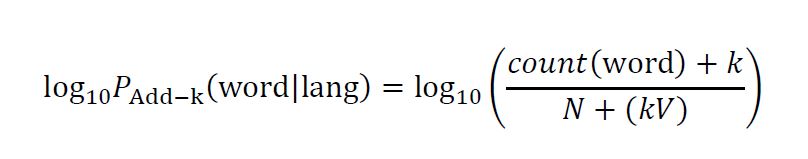
Where N is the total token count for the language model and V is the type count for the language model (1,500 for all models). The “add-k” smoothing technique was utilized to account for words that are unknown to the language models. The value of .000001 was assigned to k for these calculations. The language category of a given text is labeled as “unk” (unknown) if the percentage of recognized sentence tokens in the most probable language is less than 1/3. This condition was set in order to identify cases where data is sparse and it becomes problematic to maintain a high degree of confidence in any classification.
 |
|---|
| Results for the first input sentence. |